Qué significa “ejecutar inferencia localmente”
Ejecutar inferencia localmente significa correr un modelo de IA preentrenado directamente en tu propia máquina para generar salidas (texto, código, embeddings) sin enviar datos a la nube.
No estás entrenando un modelo. Estás cargando los pesos + ejecutando pases hacia adelante usando un runtime local.
Piénsalo como:
“Usar un modelo de IA como un binario local, no como un servicio alojado.”
Por qué ejecutar en local
La inferencia local te da control sobre distintos aspectos.
Beneficios clave
- Costo marginal cero Sin cobro por token ni cuotas mensuales de hosting.
- Iteración rápida Cambia prompts, parámetros o modelos al instante.
- Privacidad por defecto Los datos se quedan en el dispositivo; exporta solo si es necesario.
- Aprendizaje fundamental Entiendes la pila de ejecución antes de escalar a la nube o a APIs.
- Capacidad offline Útil en viajes, redes restringidas o entornos sensibles.
Cuándo es la elección correcta
- Aprender cómo corren realmente los LLMs
- Ingeniería de prompts y evaluación
- Experimentos pequeños de RAG
- Prototipar flujos antes de desplegar en la nube
Cuándo no correr en local
De forma natural, al ejecutar LLMs en local estás limitado por el hardware que tienes. Revisa tus especificaciones antes de elegir un modelo.
Sé explícito con las limitaciones para evitar frustración:
- Evita modelos grandes (30B+)
- Evita generación de imagen o video en CPUs de consumo
La inferencia local es un laboratorio, no una fábrica.
Requisitos y configuración
Antes de ejecutar algo, valida este checklist:
- El tamaño del modelo cabe en el hardware
- CPU, RAM y disco son restricciones no negociables.
- Runtime instalado
- Versión, cuantización, checksum.
- Health check correcto
- El modelo carga y responde.
- Latencia medida
- Tiempo al primer token y tokens/seg capturados.
Si el paso 5 falla → reduce el tamaño del modelo o el contexto.
Cuantización
La cuantización es una técnica que reduce el tamaño de un modelo de IA almacenando sus pesos con menor precisión numérica. Esto hace que el modelo use menos memoria y corra más rápido, especialmente en CPUs, a costa de una pequeña reducción en precisión. La cuantización es esencial para ejecutar modelos localmente en hardware de consumo, ya que permite que modelos grandes quepan en memoria y hagan inferencia de forma eficiente.
Runtimes
Un runtime es el software que ejecuta un modelo de IA en tu máquina. Carga el modelo, realiza los cálculos necesarios, gestiona recursos de hardware (CPU o GPU) y devuelve la salida generada. El mismo modelo puede sentirse rápido o lento según el runtime, porque el runtime controla el rendimiento, el uso de memoria y la compatibilidad con hardware.
Selección de modelo
- Modelos de 3B–7B parámetros
- Cuantización de 4 bits (Q4)
- Formato GGUF (para el ecosistema de llama.cpp)
Por qué esto funciona:
- Cabe en 16 GB de RAM
- Latencia aceptable en CPUs
- Aún útil para tareas de razonamiento y código
Qué observar
- Tiempo hasta el primer token
- Tokens por segundo
- Uso de memoria
- Throttling térmico si el equipo se calienta demasiado
Si responde con coherencia → ya estás listo.
Experimento práctico
En mi caso elegí llama.cpp (Github) porque tengo un Mac Intel con solo 16 GB, que no es lo suficientemente potente para correr modelos grandes.
llama.cpp
- Runtime en C++
- Enfocado en CPU, mínimo overhead
- Mejor opción para Macs Intel y hardware antiguo
- Máximo control, mínima magia
Setup mínimo (llama.cpp)
Este es el hola mundo de la inferencia local.
# instalar runtime
brew install llama.cpp
# correr un modelo cuantizado
# usando Qwen3-4B-GGUF:Q4_K_M desde Hugging Face
# cuantizacion de 4 bits
llama-server
-hf ggml-org/Qwen3-4B-GGUF:Q4_K_MEjemplo de prompt
Quiero analizar mis finanzas personales localmente. Ayúdame a explorar distintos escenarios de presupuesto y ahorro a largo plazo, y lista las variables que debería considerar antes de compartir esta información con bancos, herramientas financieras o servicios externos.
Mi situación actual:
– Ingreso neto mensual: $3,500
– Gastos fijos mensuales (renta, servicios, seguros): $1,600
– Gastos variables (comida, transporte, ocio): ~$900
– Ahorros actuales: $12,000 en efectivo
– Sin deuda de alto interés
– Meta a mediano plazo: construir un fondo de emergencia de 6 meses
– Meta a largo plazo: ahorrar para el enganche de una casa en 5–7 años
Con este escenario, ayúdame a:
- Desglosar un presupuesto mensual realista
- Explorar al menos dos estrategias de ahorro con diferentes compromisos de riesgo y flexibilidad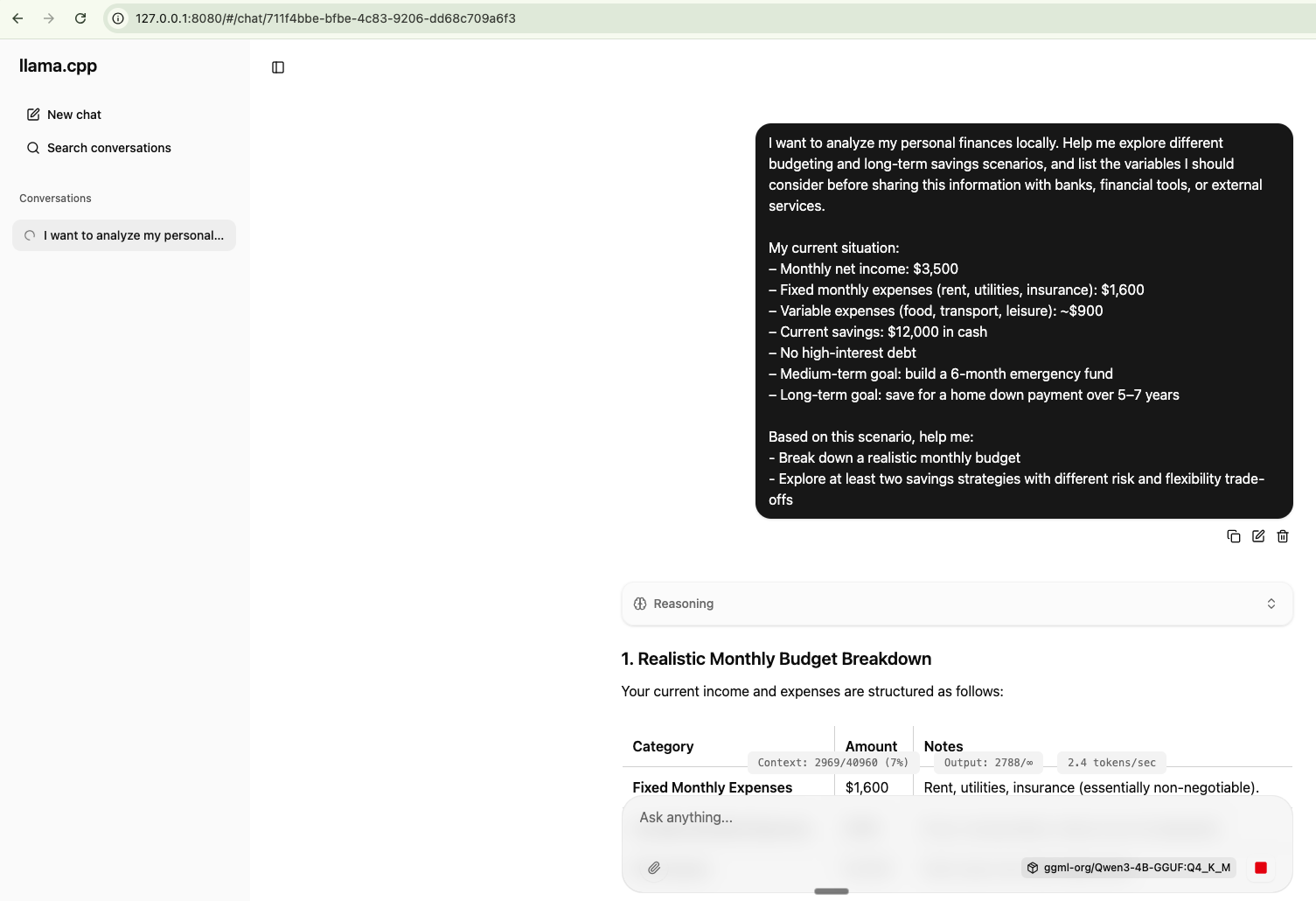
Las conversaciones pueden exportarse en formato JSON.
Para usuarios más técnicos, también es posible utilizar el runtime mediante CLI:
llama-cli -hf ggml-org/Qwen3-4B-GGUF:Q4_K_M